一、引言
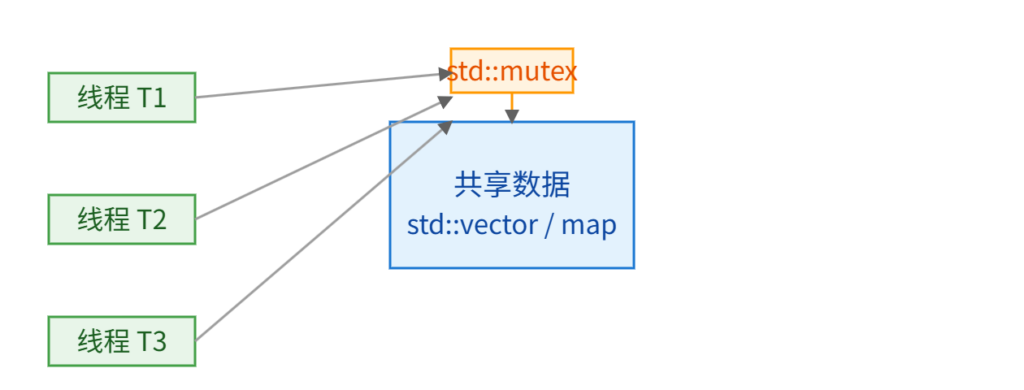
开线程本身并不难,难的是在线程之间安全地共享数据。如果一个进程里开了十几个线程,每个线程只做完全独立的计算,不读不写共享内存,那根本不需要任何同步原语,甚至单纯用函数参数和局部变量就够了。然而现实中的应用几乎不可能这么理想,你总要维护一些共享状态:请求队列、连接表、缓存、统计计数器等。一旦多个线程对同一个内存位置进行读写,问题就来了。如果不加任何约束,CPU和编译器完全可以以各种奇怪的顺序重排这些读写操作,导致某个线程看到的值和在另一个线程预期的完全不同。为了解决这种“数据竞争”,C++标准库提供了std::mutex,它的目标很简单,在同一时间,只允许一个线程进入某个临界区,其他线程必须在外面排队。
二、数据竞争的本质
想象有两个线程同时对同一个整数做++x操作,每个++x在机器代码层面大概会分成“读x”,”加一”,“写回”三个步骤。如果没有同步,两个线程的这些小步骤可以任意交错,线程A读到x=0,线程B也读到x=0,A加一,写回1,B加一写回1,最终的结果是1而不是2,这就是典型的逻辑错误。更糟的是,C++的内存模型规定,对同一内存位置的并发访问,如果存在至少一个写,且没有同步,就构成了data race(数据竞争),程序行为是未定义的,编译器甚至可以在优化时直接假设这种情况不存在,从而生成你完全想不到的代码。因此,任何共享变量,只要同时被多个线程写(或一个写多个读)就必须通过某种同步机制保护,要么用原子操作,要么用互斥锁,要么用更高级的并发容器,不能裸奔。
三、std::mutex的基本用法
std::mutex就像是通往共享数据那扇门的锁。同一时刻,只有持有这把锁的线程可以进入门后那片临界区,其他线程只能堵在门口等待。最基本的用法就是在进入临界区调用lock(),在离开的临界区的时候调用unlock()。
std::mutex m;
int counter = 0;
void worker() {
for (int i = 0; i < 100000; ++i) {
m.lock();
++counter;
m.unlock();
}
}
这种写法有两个明显的问题,一是你必须确保每个lock()调用都有配对的unlock(),否则忘记释放锁就导致其他线程永远卡死,二是如果临界区内部抛出异常或者函数提前return,很容易绕过unlock(),造成逻辑上“泄露的锁”。为了解决这个问题,C++标准库提供了RAII风格的std::lock_guard,它在构造时自动加锁,在析构时自动解锁,把“锁的生命周期”与作用域绑定到了一起:
std::mutex m;
int counter = 0;
void worker() {
for (int i = 0; i < 100000; ++i) {
std::lock_guard<std::mutex> guard(m);
++counter;
} // guard 析构,自动 m.unlock()
}
在这段代码中,只要你进入循环体,就必然会构造一个lock_guard,当离开作用域时(无论正常走到末尾还是中途return或抛异常),lock_guard的析构函数都会自动调用unlock(),这样你就不可能忘记释放锁。
四、std::unique_lock
有时你需要比lock_guard更灵活些的控制,比如希望在某个作用域的中甲暂时释放锁、或者采用条件变量的wait接口,这时就需要std::unique_lock。它同样是RAII风格,但提供了lock()、unlock()、try_lock()、等成员函数,可以在生命周期内多次锁定和释放,而且能配合std::adopt_lock等标签使用。一个典型场景是配合条件变量等待某个条件成立,在wait调用内部自动释放和重新获锁,这在之后的博客会提到。
五、std::mutex的实现
从实现的角度来看,一个std::mutex通常由两个部分组成,用户态的原子标志位和内核态的等待队列。线程在调用lock()时,首先会在用户态尝试用原子操作把这把锁从“未占用”状态切换到“占用”状态。如果成功就直接进入临界区,这条路径不经过内核,成本很低。但是如果失败,说明有别的线程已经持有这把锁,这是实现可能会稍微忙等一会(不停的检查锁的状态),希望它很快的释放,如果忙等仍然失败,就会调用系统调用(比如linux下的futex),把自己挂到内核维护的等待队列里并进入睡眠,让出CPU。当持锁线程调用unlock()时,如果发现等待队列非空,就会唤醒其中一个或多个等待线程,让它们重新参与竞争。这套设计的目标是:在轻度竞争的情况下尽可能呆在用户态,避免陷入内核。在高度竞争的情况下则通过睡眠避免浪费CPU。你可以把它想象成一扇门前的队列,如果前面没人,直接推门进去,如果前面排着队,就乖乖排队去,轮到你了再进去。
差不多是这样
七、C++内存模型与“顺便获得”的可见性保证
std::mutex出了提供可互斥访问之前,还有一个常被忽略的副作用,内存可见性和顺序保证。C++内存模型规定释放一个mutex(也就是unlock())会对随后成功获得同一把mutex的操作建立happens-before关系,简单说就是“前一个线程在临界区内做出的所有写入,在后一个线程加锁成功后一定可见”。这背后借助了内存屏障和编译器约束,你不需要直接面对std::atomic的memory order等复杂细节,只要确保所有对某个共享对象的访问都在同一把mutex保护下,就可以认为读写顺序是直观的。这一点对于避免微妙的缓存一致性bug非常重要,也让mutex成为大多数情况下的首选同步原语。
八、小结
最后小结一下,这篇总结就一句话,任何共享数据,都应该明确地挂在某一把(或某一组)mutex之下,所有读写都通过RAII风格的锁来保护,不要有“有时加锁有时裸奔”的模糊地带。在代码结构上,尽量把“锁+数据”封装在类内部,通过成员函数来对外提供操作接口,而不是到处暴露裸露的mutex,这样可以减少误用。