一、引言
很多C++程序员第一次写多线程代码时,都有类似的感受:std::thread t(f);这一行一写完,好像凭空多出一条执行线,程序自然而然就开始并行跑了。如果只停留在这个层面,你很难自觉地判断自己在做什么,譬如到底开了多少线程、这些线程在哪里跑、什么时候结束、资源谁来回收,以及它们和锁、条件变量之间到底是什么关系。要把多线程系统写稳定,就要好好了解学习std::thread真正的东西。
二、操作系统中的线程
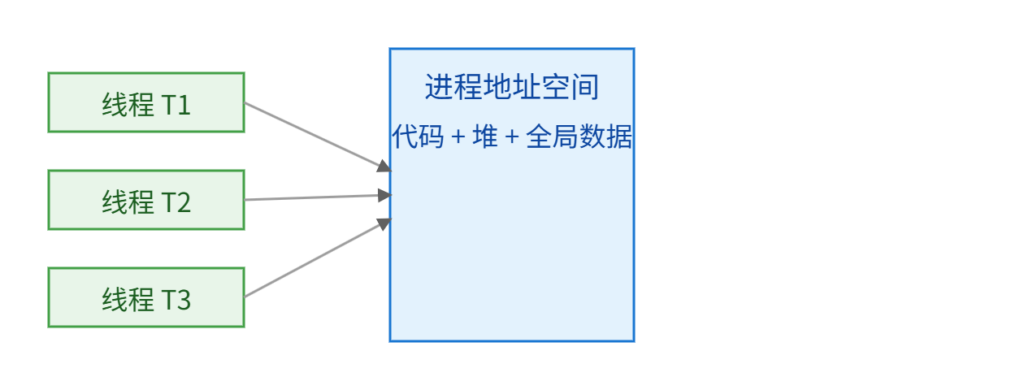
在操作系统眼里,进程是一个独立的资源容器,里面由虚拟地址空间、打开的文件、各种内核对象以及至少一条执行路径。线程则是进程内部的“可调实体”,它有自己的寄存器上下文(程序计数器、通用寄存器等)、自己的栈和线程ID,但和统一进程里的其他线程共享代码段、堆、全局数据和打开的文件。调度器真正参与调度的是线程而不是进程,它会维护一个就绪队列,在每个CPU核心空闲或时间片用完时,选择一条线程来运行。这意味着,当你在C++里创建一个std::thread时,实际上就是向操作系统提出了“请帮我创建一条新轨道,让它沿着同一个地址空间跑”的请求。下图可以帮助你在脑海里建立一个直观模型:左边是三个线程,右边是它们所属的同一个进程的地址空间,每个线程都通过内核调度器在这块空间内执行代码并访问共享数据。
三、std::thread做了什么
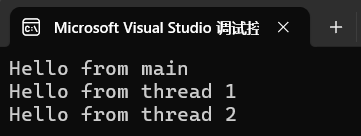
当你写下std::thread t(work,42);时,C++标准库首先会把work和参数打包成一个可调用的对象,然后用底层平台的线程创建API。在Linux上,这通常时pthread_create,它会在内核中为新线程分配TCB(线程控制块)、栈空间、初始化寄存器状态,并把入口函数设置为标准库内部的一个“启动器”,这个启动器再去调用你传进去的work,42.内核把这个新线程插入调度队列后,在某个时间点就会让它在某个CPU核心上运行,而调用std::thread构造函数的那个线程则继续往下执行。一个最小的例子就能反映出这种“主线程+工作线程”的关系:
#include <thread>
#include <iostream>
void work(int id) {
std::cout << "Hello from thread " << id << "\n";
}
int main() {
std::thread t1(work, 1);
std::thread t2(work, 2);
std::cout << "Hello from main\n";
t1.join();
t2.join();
}
这里main线程和t1、t2同时存在,每个线程都在自己的栈上执行代码,它们通过共享的标准输出流向终端打印内容、不同执行顺序下输出的行顺序可能会发生变化,但程序整体在三个线程全部接收之后才会退出。
四、线程生命周期管理
创建线程只是第一步,真正的工程问题在于如何管理他们的生命周期。每个线程结束时,都需要有一个“收尸者”来回收它占用的内核资源,比如线程栈、TCB等。在POSIX线程模型里,一个线程如果没有被pthread_join,就会留下所谓的“僵尸线程”。在C++标准库里,std::thread对象就扮演了这位“收尸者”的角色,当你调用t.join()时,当前线程会阻塞等待t对应的OS线程结束,然后内部调用底层join原语完成资源回收。如果你调用t.detach(),则表示“我不在关心这个线程何时结束”,从此std::thread对象与OS线程分离,线程结束时资源由运行时自动回收,程序再也无法join它。因此,一个非常重要的规则是:在std::thread对象销毁前,你必须显式地选择join或detach,否则程序会调用std::terminate直接结束。下面这段代码演示了错误用法和正确用法的差别:
void bad() {
std::thread t([] {
/* do something */
}); // 如果不 join / detach,t 析构时会 terminate
}
void good() {
std::thread t([] {
/* do something */
});
t.join(); // 或者 t.detach();
}
在实际的项目中,你可以把所有线程对象放入一个容器,在某个统一的收尾阶段遍历join(),这样就不会遗落任何一个线程。
五、线程数量和调度开销
每创建一个线程,都需要内核分配栈内存和控制块,同时调度器也要管理它的状态。当可运行线程多于CPU核心时,调度器需要频繁进行上下文切换,把不同线程轮流加载到CPU上。这些切换涉及保存和恢复寄存器、切换内核数据结构等,成本并不为零,因此无节制地创建线程反而会拉低性能,甚至因为栈内存耗尽而导致程序崩溃。很多工程实践的经验时:工作线程的数量不应远远大于硬件并发度,可以通过std::thread::hardware_concurrency()取一个大致估计,然后围绕这个数目设计线程池。线程池的思想很朴素:预先创建固定数量的工作线程,让它们在一个循环里不断从任务队列里取任务执行,当队列为空时通过条件变量等待。外部所有任务都丢进这个队列,而不是每来一个任务就开一个新线程。这种做法使得线程创建的开销被摊销掉,线程数量也更容易控制。理解了底层调度模型之后,你就会自然倾向于用少量线程+任务队列的方式来管理并发,而不是到处开线程,这会让你的程序在负载升高时更可预测、更稳定。
六、总结
std::thread对应着操作系统里的一个内核线程,有栈、有寄存器、有调度成本、需要被显式管理生命周期。在此基础上,我们可以进一步讨论std::mutex时如何让这些线程安全共享数据的,死锁时如何在多个线程之间形成等待环,以及条件变量如何在等待和唤醒之间搭建桥梁。下一篇,我们就从共享数据的角度切入,看看为什么几乎所有非trivial的多线程程序都离不开std::mutex。